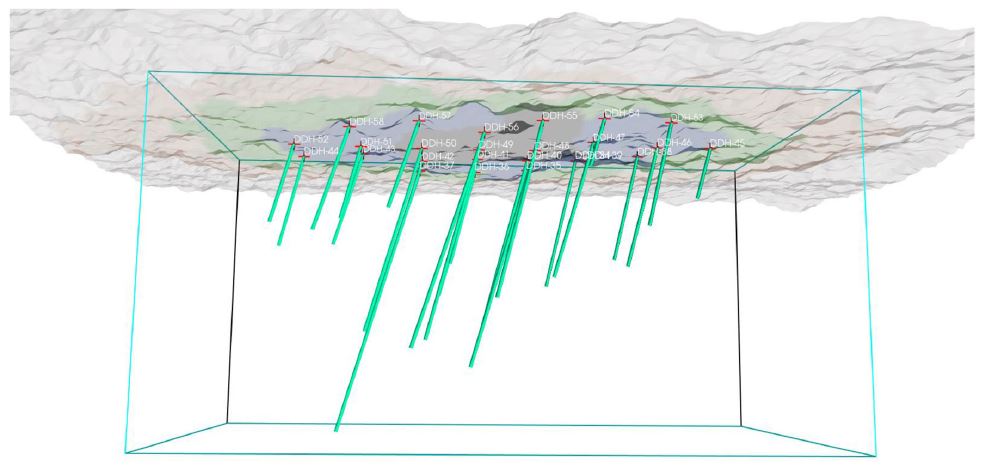
The December issue of Natural Resources Research features our paper “Simulation of Synthetic Exploration and Geometallurgical Database of Porphyry Copper Deposits for Educational Purposes” in collaboration with Mauricio Garrido (Ph.D. candidate in the Department of Geology at Universidad de Chile), who spent a short research internship in our lab. The paper is also coauthored by Dr. Exequiel Sepulveda (University of Adelaide) and Dr. Brian Townley (Universidad de Chile).
The paper can be downloaded here.
Simulation of Synthetic Exploration and Geometallurgical Database of Porphyry Copper Deposits for Educational Purposes
Mauricio Garrido (Department of Geology, Universidad de Chile), Exequiel Sepulveda (School of Civil, Environmental and Mining Engineering, The University of Adelaide), Julian Ortiz (The Robert M. Buchan Department of Mining, Queen’s University), and Brian Townley (Department of Geology, Universidad de Chile)
Abstract
The access to real geometallurgical data is very limited in practice, making it difficult for
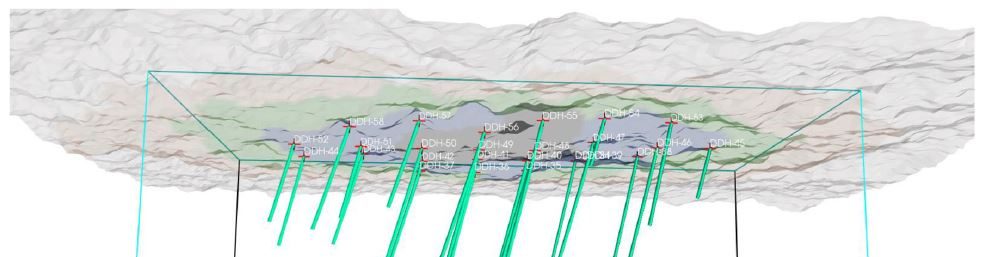
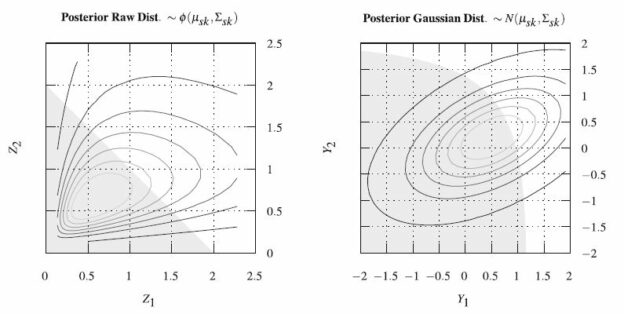
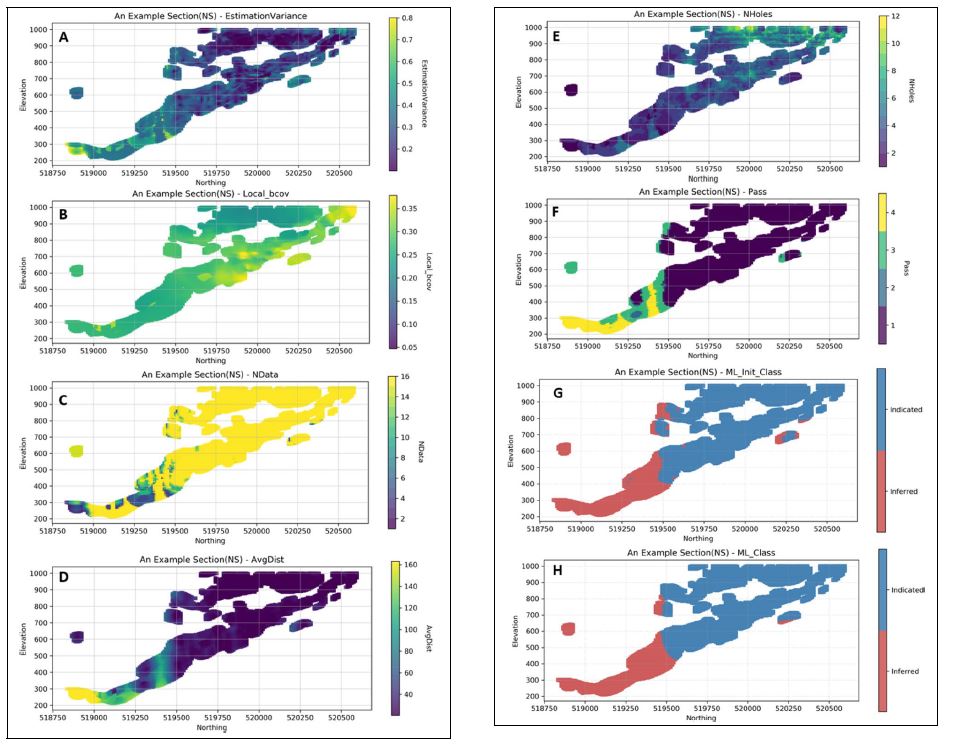
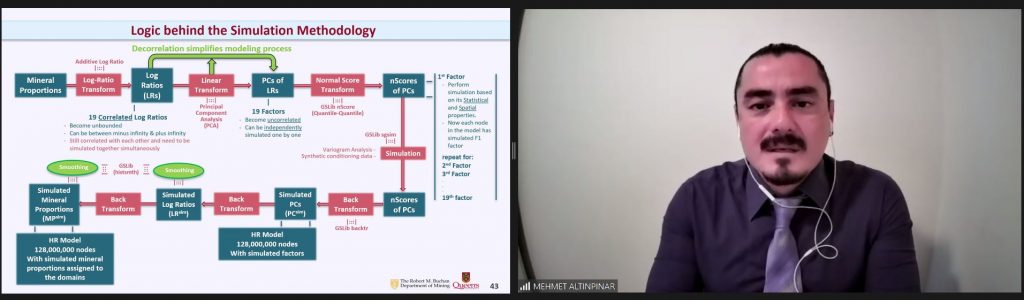
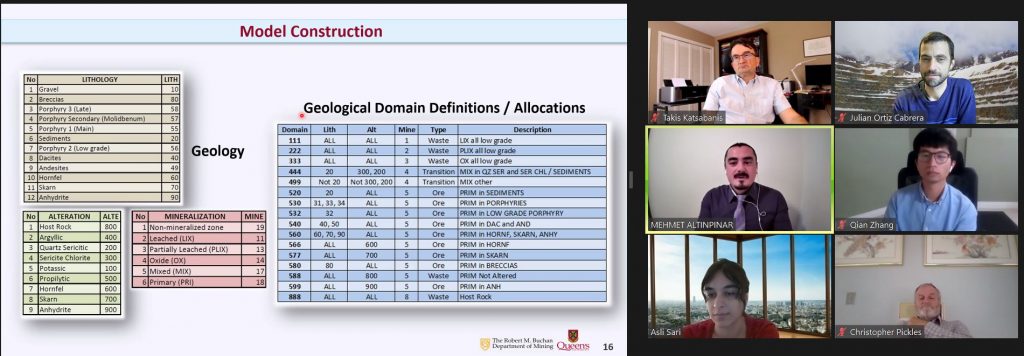
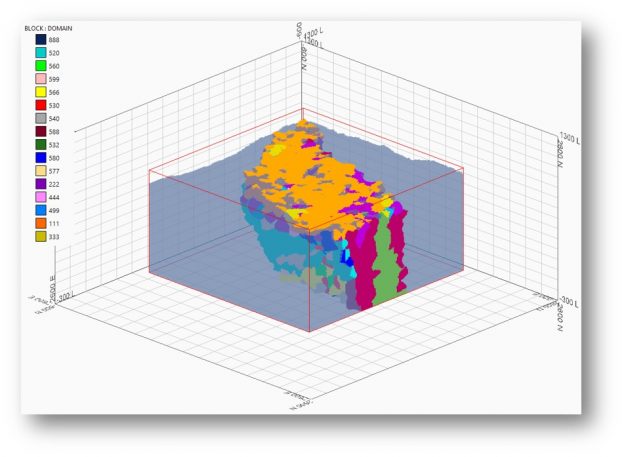
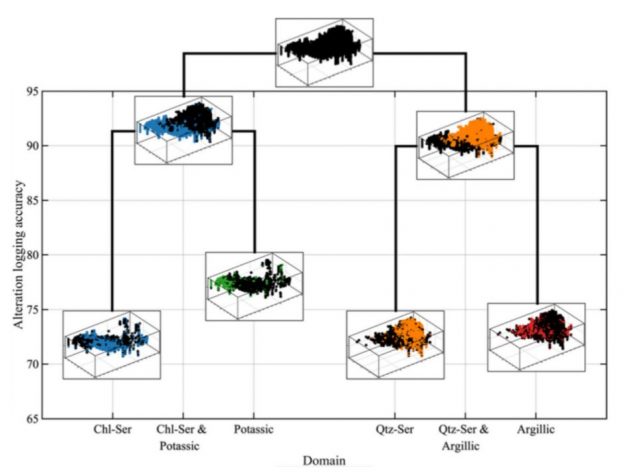
practitioners, researchers and students to test methods, models and reproduce results in the field of geometallurgy. The aim of this work is to propose a methodology to simulate geometallurgical data with geostatistical tools preserving the coherent relationship among primary attributes, such as grades and geological attributes, with mineralogy and some response attributes, for example, grindability, throughput, kinetic flotation performance and recovery. The methodology is based in three main components: (1) definition of spatial relationship between geometallurgical units, (2) cosimulation of regionalized variables with geometallurgical coherence and (3) simulation of georeferenced drill holes based on geometrical and operational constraints. The simulated geometallurgical drill holes generated look very realistic, and they are consistent with the input statistics, coherent in terms of geology and mineralogy and produce realistic processing metallurgical performance responses.
These simulations can be used for several purposes, for example, benchmarking
geometallurgical modeling methods and mine planning optimization solvers, or performing risk assessment under different blending schemes. Generated datasets are available in a public repository.