
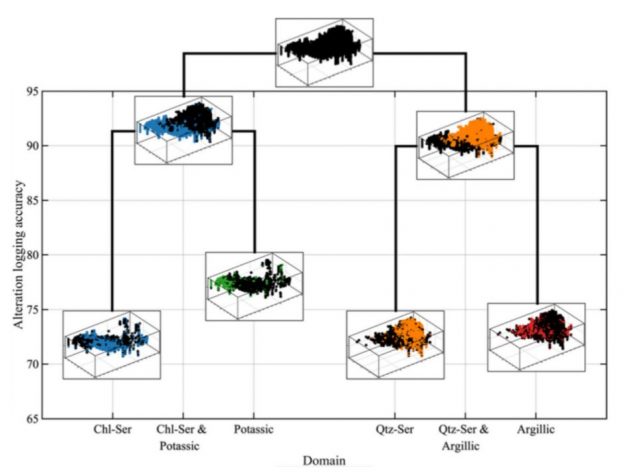
Fouad Faraj spent a summer as a graduate intern. During these months he developed an idea to apply a statistical based multivariate approach to define geological domains. The main idea is to first split the global distribution of multiple attributes (geochemical concentrations) into sub-populations that follow a parametric distribution. This leads to an optimization problem to fit these distributions. Then, every sample in the database can be allocated into one of the sub-populations, initially at random, and then samples belonging to different domains are swapped with a greedy algorithm, to reduce the MSE over the expected distribution. Amazingly, this leads to consistent spatial clusters. Domain knowledge is input during the selection of the discriminant attributes used in the first step. Theoretically this could be extended to many variables, although, as usual, a good fit of the resulting distributions would require a large number of samples (and the computational cost would increase significantly).
The full paper can be downloaded here: https://doi.org/10.1007/s42461-021-00428-5
For a limited time, the paper can be read here: https://rdcu.be/ciQlU
A Simple Unsupervised Classification Workflow for Defining Geological Domains Using Multivariate Data
by Fouad Faraj & Julian M. Ortiz
Abstract
Within the natural resource industries, there is an increasing amount of data and number of variables being recorded when sampling a site. This has made multivariate geospatial datasets more difficult to analyze, in particular the definition of estimation or simulation domains used in geostatistical analysis. Establishing these domains is typically the first step for any subsequent geostatistical workflows or modeling. Domains are traditionally established using categorical data such as lithology, mineralization, or alteration from geological logging and are aimed at identifying distinct populations with particular geological, spatial, and statistical features. The manual logging process is time-consuming and costly but is required because defining geologically homogenous volumes is crucial for the planning, extraction, and processing of natural resources. Classical clustering methods have aided in analyzing the multivariate datasets, but the resulting clusters from these methods do not correlate well with geological logging and do not allow practitioners to input their knowledge of the domain in the clustering process. In this work, a simple unsupervised classification workflow is presented which allows the practitioner to input domain knowledge by selecting relevant variables to cluster reasonable geological domains. This can be used as a tool to aid the manual logging procedure or as a tool to establish domains for different uses such as defining zones with different rock hardness distributions which allows the corresponding volumes to be sent to appropriate mills for efficient mineral processing. The performance of the workflow is assessed on a mining dataset using the geochemical information and validated with the geological logging.